Your JSON, our JSON - RAW Metadata in Archipelago
From the desk of Diego Pino
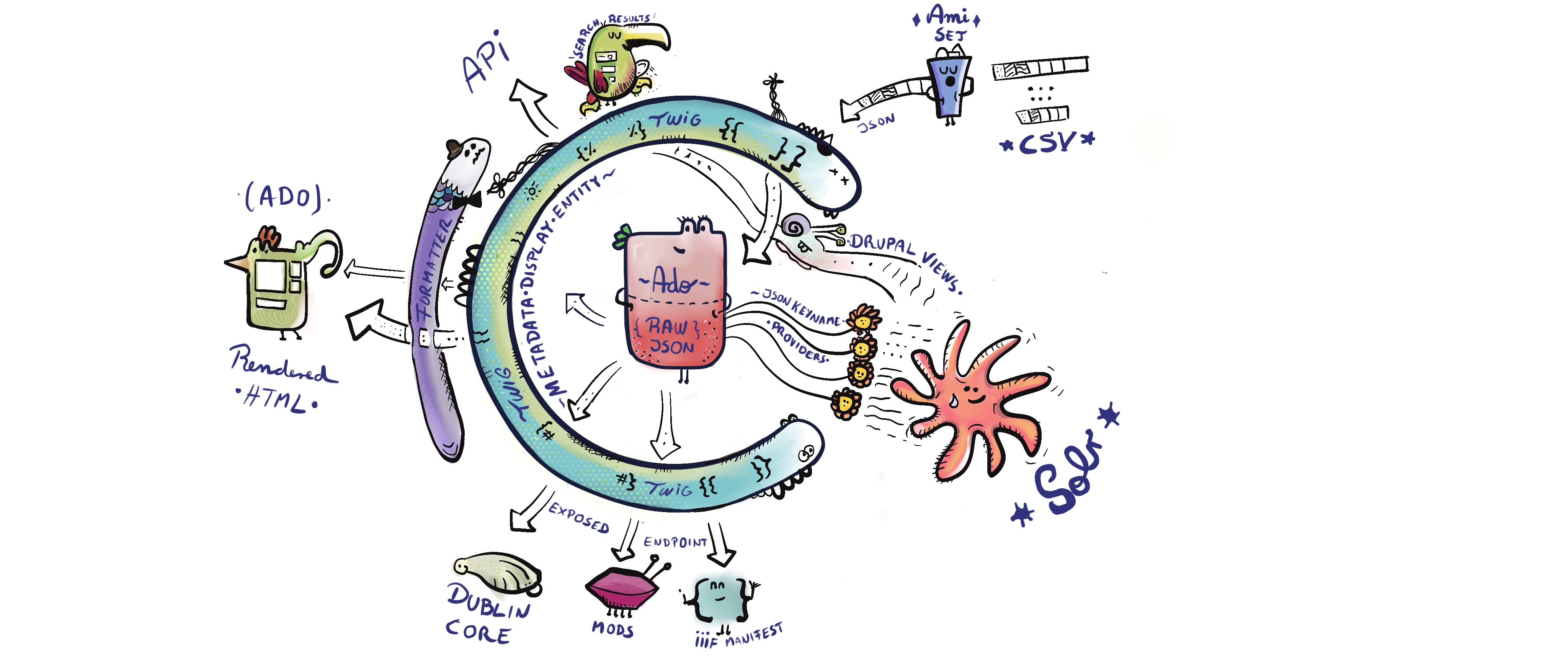
Archipelago's RAW metadata is stored as JSON and this is core to our architecture. To avoid writing RAW over and over, this document will refer to RAW Metadata simply as Metadata.
Data and Metadata can be extremely complex and extensive. The use cases that define what Data, Media and Metadata to collect, to catalog and expose, to use during search and discovery or to enable interactive functionality, including questions like "what public facing schemas, formats and serializations I need or want to be compliant with" are as diverse and complex as the Metadata driving them.
But also Metadata, in specific, is plastic and evolving as are use cases. And more over, some Metadata is descriptive and some Metadata is technical and there are other types of Metadata too, e.g Control Metadata.
Finally Metadata is very close to their generators. Means you and your peers will know, better than any Software Development team, what is needed, useful and, many times also, available given what use case you have, end users needs and resources at hand, your In real life workflows and future expectations.
Reason behind using JSON
- Complex hierarchical Metadata needs to be machinable (and fast)
- All types of Metadata might need to be "easy to access" while generating output, visualizations, search and discovery.
- The shape of this Metadata might need to change and adapt in time. Idea that supports Open Schema v/s a highly structured and fixed Schema, e.g Relational database (RDB) for most of the use cases we think Archipelago can cover.
- JSON is shareable, portable, easy to validate online and offline.
- JSON is compact.
- JSON is searchable/filterable using Query Languages like JSONPATH and JMESPATH.
- JSON is easy to patch and modify in batches.
- JSON is platform agnostic and has been around for decades and has not changed since then.
- JSON is typed and allows ordering/sorting of data easily.
Drupal and JSON
Drupal, the OSS CMS system Archipelago uses and extends, is RDB driven. This means that Content Types normally follow the idea of an Entity with Fields attached. Each of these Fields becomes then a Database Table and the sum of all these fields living under a Content Type definition, a fixed schema.
For integration and interoperability reasons with the larger Drupal ecosystem, we inherit in Archipelago the idea of an Entity, in specific, a Content Entity (Node) and Content Type (Bundled fields for a Node). But instead of generating (and encouraging) the use of hundreds of fixed fields to describe your Digital Objects we put all Metadata as JSON, means a JSON BLOB, into a single smart Field of type Strawberry Field. 🍓
We go a long way of making as much as possible flexible and dynamic. This also implies the definition (and separation) of what an Archipelago Digital Object (ADO) is in our Architecture v/s what a general Drupal Content Type (e.g a static page or a blog post) is defined in code as: "Any Content type that uses a Strawberry Field is an ADO and will be processed as such". No configuration is needed. In other words, all is a NODE but any node that uses a Strawberry Field gets a different treatment and will be named in Archipelago an ADO.
One of the challenges of our flexible approach is how to allow Drupal to access the JSON in a way, as native as possible, to generate filtered listings via Drupal Views, free text Search and Faceting. To make this happen Strawberry Field uses a JSON Querying and Exposing as "Native Field Properties" logic. Through a special type of Plugin system named Strawberry Key Name Providers and associated Configuration Entities (can be found at /admin/structure/strawberry_keynameprovider), you have control on which keys and values of your JSON are going to be exposed as field properties of any Strawberry Field, allowing Drupal through this to access values in a flat manner and expose them to the Search API natively. The access to the values of any JSON is done via JMESPATH expressions and then transformed either to a list of values or even "cast" into more complex data Data types, like an Entity Reference (means a connection to another Entity).
This gives you a lot of power and control and makes a lot of very heavy operations lighter. You can even plan upfront or evolve these properties in time.
In other words, you control how storage is mapped to Discovery and this allows Drupal Views to work that way too. Of course this also means traditional SQL based Drupal Views won't have access to these internals (for filtering) given that your JSON data nor the virtual Properties generated via Strawberry Key Name Providers are not accessible as individual RDB tables to generate SQL joins and that is why we heavily depend on the Search API (Solr).
Open Schema. What is yours, what is Archipelago's
What can you add to an ADO's Strawberry Field? As long as it is valid JSON, Archipelago can store it, display it, transform it and search across it in Archipelago. The way you manage Metadata can be as "intime" or "aligned" to other schemas as you want. Still, there are a few suggested keys/functional ideas:
Suggested JSON keys
The type key
{
"type": "Photograph"
}
The type JSON key has a semantic and functional importance in Archipelago. Given that we don't use multiple Drupal Content Types to denote the difference between e.g. a Photograph or a Painting (which would also mean you would be stuck with one or other if we did), we use this key's value to allow Archipelago to select/swap View Modes. This approach also allows for your own needs to define what an ADO in real life or digital realm is (the WHAT). This key is also important when doing AMI based batch ingests since many of the mappings and decisions (e.g. what Template to use to transform your CSV or if the Destination Drupal Content Type is going to be a Digital Object or a Digital Object Collection) will depend on this.
Note: Archipelago does something extra fun too when using type value for View Mode Selection (and this is also a feature of one of the Key Name provider Plugins). It will flatten the JSON first and then fetch all type keys. How does this in practice work?
{
"type": "Photograph",
"subtypes": [
{
"type": "125 film"
},
{
"type": "Instant film"
}
]
}
Means, while doing a View Mode Selection Archipelago will bring all found type key values together and will have ['Photograph', '125 film', 'Instant film'] available as choices, meaning you will be able to make even finer decisions on how to display your ADOs. View Mode selection is based on order or evaluation, means we recommend putting the more specific mappings first.
The label key
{
"label": "Black and White Photograph of Cataloger working with JSON"
}
Archipelago will use the label key's value to populate the ADO's (Drupal Node) Title. Drupal has a length limit for its native build in Node Entity Title but JSON has not, so in case of more than 255 characters Archipelago will truncate the Title (not the label key's value) adding an ellipsis (...) as suffix.
Archipelago Drupal Entities integration keys
Because of the need of having Technical Metadata, Descriptive Metadata and Semantic Metadata while generating different representations of your JSON via Metadata Display Entities (Twig templates) transformations, we store and characterize Files attached to an ADO as part of the JSON. We also use a set of special keys to map and cast JSON keys and values to Drupal's internal Entities system via their Numeric and/or UUID IDs.
Through this, Archipelago will also move files between upload locations and permanent storage, execute Technical metadata extraction, keep track of ADO to ADO relationships (e.g ispartof or ismemberof) and emulate what a traditional Drupal Entity Reference field would do without the limitations (speed and immutability) a static RDB definition imposes.
The ap:entitymapping key
{
"ap:entitymapping":{
"entity:file": [
"model",
"audios",
"images",
"videos",
"documents",
"upload_associated_warcs"
],
"entity:node": [
"ispartof",
"ismemberof"
]
}
}
the ap:entitymapping is a hint for Archipelago. With this key we can treat certain keys and their values as Drupal Numeric Entity IDs instead of semantically unknown values.
In the presence of the structure exemplified above the following JSON snipped:
"images": [
1,
2,
3
]
Will tell Archipelago that the JSON key images should be treated as containing Entity IDs for a Drupal Entity of type (entity:file) File. This has many interessting consequences. Archipelago, on edit/update/ingest will try (hard) to get a hold of Files with ID 1, 2 and 3. If in temporary storage Arhcipelago will move them to its final Permanent Location, will make sure Drupal knows those files are being used by this ADO, will run multiple Technical Metadata Extractions and classify internally the Files, adding everything it could learn from them. In practice, this means that Archipelago will write for you additional structures into the JSON enriching your Metadata.
Without this structure, the images key would not trigger any logic but will of course still exist and can always still be used as a list of numbers while templating.
This also implies that for a persisted ADO with those values, if you edit the JSON and delete e.g. the number (integer or string representation of an integer) 3, Archipelago will disconnect the File Entity with ID 3 from this ADO, remove the enriched metadata and mark the File as not being anymore used by this ADO. If nobody else is using the File it will become temporary and eventually be automatically removed from the system, if that is setup at the Drupal - Filesystem - level.
Using the same example ap:entitymapping structure, the following snippet:
"ispartof": [
2000
]
Will hint to Archipelago on assumed connection between this ADO and another ADO with Drupal Entity ID 2000. This will drive other functionality in Archipelago (semantic), allowing for example a Navigation Breadcrumb to be built using all connections found in its hierarchical path.
In Archipelago ADO to ADO relationships are normally from Child to Parent and hopefully (but not enforced!) building an Acyclic graph, from leaves to trunk. This will also allow inheritance to happen. This means also that a Parent ADO needs to exist before connecting/relating to it (chicken first). But if it does not, the system will not fail and assume a temporarily broken relationship (egg stays safely intact).
Entity mapping key also drives a very special compatibility addition to any ADO. Archipelago will populate Native Computed Drupal fields (attached at run time to each ADO) with these values loading and exposing them as Drupal Entities, processing both Files and Node Entities and making them visible outside the scope of a Strawberry Field to the whole CMS.
The following Computed fields are provided:
field_file_drop: Computed Entity Reference Field. Needed also for JSON API level upload of Files to an ADO (Drupal need). It will expose all File Entities referenced in an ADO, independently of the type of the File.field_sbf_nodetonode: Computed Entity Reference Field. It will expose all Nodes (other ADOs) Entities referenced in an ADO, independently of the Content type and/or the semantic predicate (ismemberof, ispartof, etc) used.
These Fields, because of their native Drupal nature, can be used directly everywhere, e.g. in the Search API to index all related ADOs (or any of their Fields and subproperties, even deeply chained, tree down) without having to specify what predicate is used. Said differently, they act as aggregators, as a generic "isrelatedto" property bringing all together.
The as:{AS_FILE_TYPE} keys
As explained in the ap:entitymapping section above, when Archipelago gets hold of a File entity it will enrich your JSON with its extracted data. Archipelago will compute and append to your JSON a set of controlled as:{AS_FILE_TYPE} keys containing a classified File's Metadata. The naming will be automatic based on grouping Files by their Mime Types.
The possible values for as:{AS_FILE_TYPE} are
as:imageas:documentas:videoas:audioas:applicationas:textas:modelas:multipartas:message
An example for an Image attached to an ADO:
{
"as:image": {
"urn:uuid:ef596613-b2e7-444e-865d-efabbf1c59b0": {
"url": "s3:\/\/de2\/image-f6268bde41a39874bc69e57ac70d9764-view-ef596613-b2e7-444e-865d-efabbf1c59b0.jp2",
"name": "f6268bde41a39874bc69e57ac70d9764_view.jp2",
"tags": [],
"type": "Image",
"dr:fid": 7461,
"dr:for": "images",
"dr:uuid": "ef596613-b2e7-444e-865d-efabbf1c59b0",
"checksum": "de2862d4accf5165d32cd0c3db7e7123",
"flv:exif": {
"FileSize": "932 KiB",
"MIMEType": "image\/jp2",
"ImageSize": "1375x2029",
"ColorSpace": "sRGB",
"ImageWidth": 1375,
"ImageHeight": 2029
},
"sequence": 1,
"flv:pronom": {
"label": "JP2 (JPEG 2000 part 1)",
"mimetype": "image\/jp2",
"pronom_id": "info:pronom\/x-fmt\/392",
"detection_type": "signature"
},
"dr:filesize": 954064,
"dr:mimetype": "image\/jp2",
"crypHashFunc": "md5",
"flv:identify": {
"1": {
"width": "1375",
"format": "JP2",
"height": "2029",
"orientation": "Undefined"
}
}
}
}
}
That is a lot of Metadata! But to understand what is happening here, we need to dissect this into more readable chunks. Let's start with the basics from root to leaves of this hierarchy.
Direct File level Metadata
Every Classified File inside the as:{AS_FILE_TYPE} key will be contained in a unique URN JSON Object property:
"urn:uuid:ef596613-b2e7-444e-865d-efabbf1c59b0": {}
We use a Property instead of a "List or Array" of Technical Metadata because this allows us (at code level) to access quickly from e.g. as:image structure all the data for a File Entity with UUID ef596613-b2e7-444e-865d-efabbf1c59b0 without iterating. (Also now you know what urn:uuid:ef596613-b2e7-444e-865d-efabbf1c59b0 means.)
Next, inside that property, the following Data provides basic Information about the File so you can access/make decisions when Templating. Notice the duplication of similar data at different levels. Duplication is on purpose and again, allows you to access certain JSON values (or filter) quicker without having to go to other keys or hierarchies to make decisions.
{
"url": "s3:\/\/de2\/image-f6268bde41a39874bc69e57ac70d9764-view-ef596613-b2e7-444e-865d-efabbf1c59b0.jp2",
"name": "Original Name of my Image.jp2",
"tags": [],
"type": "Image",
"dr:fid": 3,
"dr:for": "images",
"dr:uuid": "ef596613-b2e7-444e-865d-efabbf1c59b0",
"crypHashFunc": "md5",
"checksum": "de2862d4accf5165d32cd0c3db7e7123",
"dr:filesize": 954064,
"dr:mimetype": "image\/jp2",
"sequence": 1
"url": Contains the Final Storage location/URI of the File. It's prefixed with the configured Streamwrapper, a functional symbolic link to the underlying complexities of the backend storage. e.gs3://implies an S3 API backend with a (hidden/abstracted) set of credentials, Bucket and Prefixes inside the bucket. This value is also used in Archipelago's IIIF Cantaloupe Service as the Imageidwhen building a IIIF Image API URL."name": The Original Name of the File. Can be used to give a Download a human readable name or as an internal hint/preservation for you."tags": Unused by default. You can use this for your own logic if needed."type": A redundant (contextual, at this level) key whose value will match{AS_FILE_TYPE}already found at 2 levels before. Allows you to know what File type this is when iterating over this File's data (without having to look back, or on our Code, when dealing with Flattened JSON)."dr:fid": The Drupal Entity Numeric ID."dr:for": Where in your JSON (top level key) this File ID was stored (or in other words where you can find the value of"dr:fid". All this will match / was be driven of course byap:entitymapping. Sometimes (try uploading a WARC file and run the queue) this key might containflv:{ACTIVE_STRAWBERRY_RUNNERS_CONFIG_ID}. This means the File will have been generated by an active Strawberry Runners Processor and not uploaded by you.ACTIVE_STRAWBERRY_RUNNERS_CONFIG_IDwill be the Machine name (or ID) of a given Strawberry Runners Processor Configuration Entity."dr:uuid": A redundant (contextual, at this level) key whose value will match the Drupal File entity UUID for this File."crypHashFunc": What Cryptographic function was used for generating the checksum. By default Archipelago will do MD5 (faster but also because S3 APIs use that to ensure upload consistency and E-tag). In the future others can be enabled and made configurable"checksum": The Checksum (calculated) of this File via"crypHashFunc""dr:filesize": The File size in Bytes."dr:mimetype": The Drupal level infered Mime Type. Archipelago extends this list. This is based on the File Extension."sequence": A number (integer) denoting order of this file relative to other files of the same type inside the JSON. Which default type ordering is used will depend on how the ADO was created/edited, but can be overriden using Control Metadata.
Technical File level Metadata
Deeper inside this structure Archipelago will produce Extracted Technical Metadata. Some of this Metadata will be common to every File Type, some will be specific to a subset, like Moving Media or PDFs. What runs and how it runs can be configured at the File Persister Service Settings configuration form found at/admin/config/archipelago/filepersisting. Why there? These are service that run syncroniusly on ADO save (Create/Edit) and in while doing File persistance.
"flv:exif": EXIF Tool extraction for a file. The number of elements that come out might vary, for an Image file it might be normally short, but a PDF might have a very extensive and long list.
The above mentioned File Persister Service Settings form allows you to also set a Files Cap Number, that will, once reached, limit and reduce the EXIF. This is very useful if you want to control the size of your complete JSON for any reason you feel that is needed (performance, readability, etc).
{
"flv:exif": {
"FileSize": "932 KiB",
"MIMEType": "image\/jp2",
"ImageSize": "1375x2029",
"ColorSpace": "sRGB",
"ImageWidth": 1375,
"ImageHeight": 2029
},
}
"flv:identify": Graphics Magic Identity binary will run on every file and format it knows how to run (and will try even on the ones it does not). Will give you data similar to EXIF but processed based on the actual File and not just extracted from the EXIF data found at the header. Notice that the details will be inside a "1", "2", etc property. This is because Identify might also go deeper and for e.g a Multi Layer Tiff extract different sequences on the same File.
{
"flv:identify": {
"1": {
"width": "1375",
"format": "JP2",
"height": "2029",
"orientation": "Undefined"
}
}
}
"flv:pronom": Droid, a File Signature detection tool will find a matching pronom_idfor your File based on https://www.nationalarchives.gov.uk/aboutapps/pronom/droid-signature-files.htm. This detection type is deeper that EXIF or the mime type based on extension, reading from binary data. It allows you to get small differences between formats (even if e.g both are JP2) and thus make decisions like "Will Cantaloupe IIIF Image Server be able to handle this type?". This has also positive Digital Preservation consequences.
{
"flv:pronom": {
"label": "JP2 (JPEG 2000 part 1)",
"mimetype": "image\/jp2",
"pronom_id": "info:pronom\/x-fmt\/392",
"detection_type": "signature"
},
}
"flv:mediainfo": Media Info works on Video and Audio. It goes very detailed into codecs andstreams and the output added to your JSON might look massive. This is also very needed when working with IIIF Manifests and deciding if a certain Video will be able to play natively on a browser or if Cantaloupe IIIF Image Server will be able to extract individual frames as images. This again has positive Digital Preservation consequences. The Following is an example of an MP4 file generated via Quicktime on an Apple MacOS computer.
{
"flv:mediainfo": {
"menus": [],
"audios": [
{
"id": {
"fullName": "1",
"shortName": "1"
},
"count": "282",
"title": "Core Media Audio",
"format": {
"fullName": "AAC LC",
"shortName": "AAC"
},
"bit_rate": {
"textValue": "85.3 kb\/s",
"absoluteValue": 85264
},
"codec_id": "mp4a-40-2",
"duration": {
"milliseconds": 21215
},
"channel_s": {
"textValue": "1 channel",
"absoluteValue": 1
},
"frame_rate": {
"textValue": "43.066 FPS (1024 SPF)",
"absoluteValue": 43
},
"format_info": "Advanced Audio Codec Low Complexity",
"frame_count": "914",
"stream_size": {
"bit": 226109
},
"streamorder": "0",
"tagged_date": "UTC 2017-12-05 17:14:10",
"encoded_date": "UTC 2017-12-05 17:14:07",
"source_delay": "-0",
"bit_rate_mode": {
"fullName": "Variable",
"shortName": "VBR"
},
"samples_count": "935582",
"sampling_rate": {
"textValue": "44.1 kHz",
"absoluteValue": 44100
},
"channel_layout": "C",
"kind_of_stream": {
"fullName": "Audio",
"shortName": "Audio"
},
"commercial_name": "AAC",
"source_duration": [
"21269",
"21 s 269 ms",
"21 s 269 ms",
"21 s 269 ms",
"00:00:21.269"
],
"compression_mode": {
"fullName": "Lossy",
"shortName": "Lossy"
},
"channel_positions": {
"fullName": "1\/0\/0",
"shortName": "Front: C"
},
"samples_per_frame": "1024",
"stream_identifier": "0",
"source_frame_count": "916",
"source_stream_size": [
"226460",
"221 KiB (1%)",
"221 KiB",
"221 KiB",
"221 KiB",
"221.2 KiB",
"221 KiB (1%)"
],
"source_delay_source": "Container",
"format_additionalfeatures": "LC",
"proportion_of_this_stream": "0.01178",
"count_of_stream_of_this_kind": "1",
"source_streamsize_proportion": "0.01180"
}
],
"images": [],
"others": [
{
"type": "meta",
"count": "188",
"duration": {
"milliseconds": 21215
},
"frame_count": "1",
"kind_of_stream": {
"fullName": "Other",
"shortName": "Other"
},
"stream_identifier": [
"0",
"1"
],
"count_of_stream_of_this_kind": "2"
},
{
"type": "meta",
"count": "188",
"duration": {
"milliseconds": 21215
},
"frame_count": "1",
"kind_of_stream": {
"fullName": "Other",
"shortName": "Other"
},
"stream_identifier": [
"1",
"2"
],
"count_of_stream_of_this_kind": "2"
}
],
"videos": [
{
"id": {
"fullName": "2",
"shortName": "2"
},
"count": "380",
"title": "Core Media Video",
"width": {
"textValue": "1 280 pixels",
"absoluteValue": 1280
},
"format": {
"fullName": "AVC",
"shortName": "AVC"
},
"height": {
"textValue": "720 pixels",
"absoluteValue": 720
},
"bit_rate": {
"textValue": "7 144 kb\/s",
"absoluteValue": 7144261
},
"codec_id": "avc1",
"duration": {
"milliseconds": 21215
},
"rotation": "0.000",
"bit_depth": {
"textValue": "8 bits",
"absoluteValue": 8
},
"scan_type": {
"fullName": "Progressive",
"shortName": "Progressive"
},
"format_url": "http:\/\/developers.videolan.org\/x264.html",
"frame_rate": {
"textValue": "29.970 (29970\/1000) FPS",
"absoluteValue": 29
},
"buffer_size": "768000",
"color_range": "Limited",
"color_space": "YUV",
"format_info": "Advanced Video Codec",
"frame_count": "636",
"stream_size": {
"bit": 18951244
},
"streamorder": "1",
"tagged_date": "UTC 2017-12-05 17:14:10",
"encoded_date": "UTC 2017-12-05 17:14:07",
"bit_rate_mode": {
"fullName": "Variable",
"shortName": "VBR"
},
"codec_id_info": "Advanced Video Coding",
"framerate_den": "1000",
"framerate_num": "29970",
"sampled_width": "1280",
"format_profile": "Main@L3.1",
"kind_of_stream": {
"fullName": "Video",
"shortName": "Video"
},
"sampled_height": "720",
"color_primaries": "BT.709",
"commercial_name": "AVC",
"format_settings": "CABAC \/ 2 Ref Frames",
"frame_rate_mode": {
"fullName": "Variable",
"shortName": "VFR"
},
"bits_pixel_frame": "0.259",
"maximum_bit_rate": {
"textValue": "768 kb\/s",
"absoluteValue": 768000
},
"stream_identifier": "0",
"chroma_subsampling": [
"4:2:0",
"4:2:0"
],
"maximum_frame_rate": [
"30.000",
"30.000 FPS"
],
"minimum_frame_rate": [
"28.571",
"28.571 FPS"
],
"pixel_aspect_ratio": "1.000",
"colour_range_source": "Stream",
"format_settings_gop": "M=2, N=30",
"internet_media_type": "video\/H264",
"matrix_coefficients": "BT.709",
"original_frame_rate": [
"25.000",
"25.000 FPS"
],
"display_aspect_ratio": {
"textValue": "16:9",
"absoluteValue": 1.778
},
"format_settings_cabac": {
"fullName": "Yes",
"shortName": "Yes"
},
"codec_configuration_box": "avcC",
"colour_primaries_source": "Container \/ Stream",
"transfer_characteristics": "BT.709",
"proportion_of_this_stream": "0.98734",
"colour_description_present": "Yes",
"matrix_coefficients_source": "Container \/ Stream",
"count_of_stream_of_this_kind": "1",
"transfer_characteristics_source": "Container \/ Stream",
"format_settings_reference_frames": [
"2",
"2 frames"
],
"colour_description_present_source": "Container \/ Stream"
}
],
"general": {
"count": "336",
"format": {
"fullName": "MPEG-4",
"shortName": "MPEG-4"
},
"codec_id": [
"qt ",
"qt 0000.00 (qt )"
],
"datasize": "19177730",
"duration": {
"milliseconds": 21215
},
"file_name": "c98e7bc52e4bd3fe5681a746f2d9c76f_diego4",
"file_size": {
"bit": 19194157
},
"footersize": "0",
"frame_rate": {
"textValue": "29.970 FPS",
"absoluteValue": 29
},
"headersize": "16427",
"othercount": "2",
"folder_name": "\/tmp\/ami\/setfiles\/cb606b13b823eaea784dc77c460f3baf",
"frame_count": "636",
"stream_size": {
"bit": 16804
},
"tagged_date": "UTC 2017-12-05 17:14:10",
"audio_codecs": "AAC LC",
"codec_id_url": "http:\/\/www.apple.com\/quicktime\/download\/standalone.html",
"codecs_video": "AVC",
"encoded_date": "UTC 2017-12-05 17:14:07",
"isstreamable": "Yes",
"complete_name": "\/tmp\/ami\/setfiles\/cb606b13b823eaea784dc77c460f3baf\/c98e7bc52e4bd3fe5681a746f2d9c76f_diego4.m4v",
"file_extension": "m4v",
"format_profile": "QuickTime",
"kind_of_stream": {
"fullName": "General",
"shortName": "General"
},
"codecid_version": "0000.00",
"commercial_name": "MPEG-4",
"writing_library": {
"fullName": "Apple QuickTime",
"shortName": "Apple QuickTime"
},
"overall_bit_rate": {
"fullName": "7 238 kb\/s",
"shortName": "7237957"
},
"audio_format_list": "AAC LC",
"stream_identifier": "0",
"video_format_list": "AVC",
"codecid_compatible": "qt ",
"file_name_extension": "c98e7bc52e4bd3fe5681a746f2d9c76f_diego4.m4v",
"internet_media_type": "video\/mp4",
"encoded_library_name": "Apple QuickTime",
"comapplequicktimemake": "Apple",
"overall_bit_rate_mode": {
"fullName": "Variable",
"shortName": "VBR"
},
"comapplequicktimemodel": "iPhone SE",
"count_of_audio_streams": "1",
"count_of_video_streams": "1",
"comapplequicktimesoftware": "10.3.2",
"proportion_of_this_stream": "0.00088",
"audio_format_withhint_list": "AAC LC",
"video_format_withhint_list": "AVC",
"file_last_modification_date": {
"date": "2022-10-19 20:02:32.000000",
"timezone": "UTC",
"timezone_type": 3
},
"count_of_stream_of_this_kind": "1",
"comapplequicktimecreationdate": "2017-10-25T16:58:17-0400",
"format_extensions_usually_used": "braw mov mp4 m4v m4a m4b m4p m4r 3ga 3gpa 3gpp 3gp 3gpp2 3g2 k3g jpm jpx mqv ismv isma ismt f4a f4b f4v",
"comapplequicktimelocationiso6709": "+40.6145-074.2678+020.977\/",
"file_last_modification_date_local": {
"date": "2022-10-19 20:02:32.000000",
"timezone": "America\/New_York",
"timezone_type": 3
}
},
"version": "21.09",
"subtitles": []
}
}
}
"flv:pdfinfo": PDF Info will get Page level Information for a PDF or Ghostscript document. The dimensions displayed in the following example are not in pixels but points (resolution independent) and are also used for IIIF generation when deciding at what rasterized pixel size a given PDF document page will be rendered. Same as with flv:identify, the technical metadata will be contained inside a keyed (string but semantically an integer) property. In this particular case each number is a page sequence in the original PDF order.
{
"flv:pdfinfo": {
"1": {
"width": "612",
"height": "792",
"rotation": "0",
"orientation": "TopLeft"
}
}
}
@TODO: add the extra special key used by Strawberry Runners when it attaches a file. e.g WARC to WACZ
Did you #know?
If you delete a whole as:{AS_FILE_TYPE} structure or one of the File level structures (a urn:uuid:{uuid} key and its children), Archipelago will recreate it. If you modify any internal value contained in it, Archipelago will do nothing and will trust you (and if you do strange things like modifying the url something might even fail e.g in a IIIF Metadata Display Entity Twig Template). No data edit there will trigger a modification/moving/deletion of a File (or e.g write back EXIF to be binary). You will have time to revert to a previous revision (version) of the ADO if any manual change was done. So, should you modify/delete this structures? Almost never. Ever. But you might find needs for that someday. Also to be noted. Producing this structure for a large file in S3:// is intensive. It needs to be downloaded to a local path and if the File is a few Gigabytes in size Archipelago might even run out of PHP processing time. If that ever happens you can also copy/paste from a previous revision of the ADO the relevant piece. If archipelago finds it (implied in the previous explanation) it will not have to regenerate it. The AMI module does this in an async/enqueued way to avoid time out issues and can reuse a cached metadata extraction between runs, but when working directly on an ADO via e.g a webform or via RAW edit, take that in account.
More work is being done to allow also one on one async File operations and larger uploads via the web.
The ap:tasks keys
As mentioned briefly before, there is also Control Metadata. What do we mean with that? Control metadata in Archipelago's way of allowing you to give, through metadata, (that you might want to preserve or not) instructions to Archipelago that relate to processing. Let's start with the basic one:
{
"ap:tasks": {
"ap:sortfiles": "index"
}
}
"ap:sortfiles" key will instruct Archipelago to sort (create a sequence key and a sequential number (integer value) inside each Metadata File entry of a as:{AS_FILE_TYPE} structure. Values can be one of ['natural', 'index', 'manual'] defaulting, if absent or has an invalid value, to natural.
- natural: files will be sorted by File Name, the filename key found at the same level of sequence in the previously mentioned as:{AS_FILE_TYPE} structure. a Photograph_1.jpeg will come before a Photograph_10.jpeg. The way a human being naturally would order by name.
- index files will be sorted by the order in which they appear inside the upload JSON key (the dr:for key, one of the keys mapped in the ap:entitymapping structure under entity:file explained before. e.g. images:[5, 10 , 1 ], would imply the File Entity with Drupal ID 5 would get "sequence": 1, the one with Drupal ID 10 will get "sequence": 1, etc. This is the default when ingesting via the AMI module given the need to preserve file order that has/might have unknown names or names you don't have control of (thus natural won't work) coming from e.g a Remote, HTTP/HTTPS location
- manual: You can modify the values manually for any sequence key inside as:{AS_FILE_TYPE} structure and those values will stick.
What do we mean with stick? Well, everytime archipelago gets a change in this "ap:sortfiles", e.g a new File is added, a File is deleted, automatic re-sorting will happen.
{
"ap:tasks": {
"ap:forcepost": true
}
}
"ap:forcepost": A boolean. The functionality of this key is provided by the Strawberry Runners Module. Will force Strawberry Runners Post processing for this ADO.
Each Configured and active Postprocessor provided by the Strawberry Runners module might or not kick in by evaluating a set of rules. If rule evaluates to TRUE, the PostProcessor will generate a certain output., e.g a Solr Indexed Strawberry Flavor Data Source containing OCR, HOCR and NLP metadata for one or more pages of a PDF.
Everytime a Create or Update operation on an ADO happens, these rules will be evaluated and the Processor will be enqueued as a future task. But at the moment of executing, when the queue workers take one item, a check will be made and if the result of a previous run (e.g HOCR) is already present in the system (e.g in Solr) and it's veryfied to be belonging to the same source, the actual heavyload of processing the PDF will be skipped.
While testing, coding, doing complex changes in the system (like modifying largely the settings for one processor) or even in the case of an ISSUE (e.g HOCR was wrongly run with a setting that made all look like garbage!) you can instruct Archipelago run again without checks. And again. And again. basically everytime you Save an ADO by setting ap:forcepost to true. This can also be used batch and is already implied (means it does it for you but only once, without modifying the JSON) in the Trigger Strawberrry Runners process/reprocess for Archipelago Digital Objects VBO action we provide.
In the absence of "ap:forcepost" the value is implicitly false, same as setting it explicitly to false.
{
"ap:tasks": {
"ap:nopost": [
'pager'
]
}
}
"ap:nopost": an array or list of ACTIVE_STRAWBERRY_RUNNERS_CONFIG_ID entries, means Machine names (or IDs) Strawberry Runners Processor Configuration Entities. The functionality of this key is provided by the Strawberry Runners. If not an array it will be ignored. Any value present not matching an active Strawberry Runners Processor Configuration Entity ID will also be ignored. Effectively, any post processors in this list will be skipped for this ADO. This allows a finer grained avoidance of some expensive processing that might lead to unsuable data. E.g a particular Manuscript ADO that Tesseract won't be able to OCR correctly. Adding this key to an ADO that was already processed won't remove existing generated/stored processing.
{
"ap:tasks": {
"ap:ami": {
"metadata_display": 7
}
}
}
"ap:ami" is a newer key ( as of Archipelago 1.1.0 and AMI 0.5.0) and for now can only contain another single key named "metadata_display". The value of this one can be either a single Integer, the Drupal ID of a Metadata Display Entity or a string, the UUID of a Metadata Display Entity.
The functionality triggered by this key is provided by the AMI module and will do something extremely powerfull: it will take the complete JSON and process through the Twig or Metadata Display Entity refererenced in its value, IF, and only IF, the output of that template is JSON. This runs before any other event (Archipelago runs a ton of events that validate, enrich, check, etc your ADOs from the moment you SAVE or Create it) and because of that allows you to totally pivot, transform, change RAW data coming into Archipelago, e.g via the JSON:API into the structure you need/want.
Said differently, you could push JSON from a totally different system and if the referenced Metadata Display Entity is well written, end with a perfectly aligned JSON matching your internal structure without modifying the INPUT manually. Because Twig is very powerful you can also do cleanups, complex logic, etc. More over, you can transform any existing ADO via Batch by adding this key(s) and values using the JSON Patch VBO action. Once processed and if all went well, meaning the output of the Template is valid JSON, the key itself will be removed. This, to avoid running over and over (invisibly to you) on further operations/edits/etc.
This is a one time operation that does not stick. What happens if it does not run well, fails, errors out or the Template referenced does not exist? You get a second change (everyone deserves one), the Original ingested JSON, without transformations is kept. All this is very similar to what the AMI module does via a CSV but in this case its atomic. We know what you are thinking. You can process data twice, via AMI and then at the end pass it again through another template based on a certain logic coming from the first? yes. you can!
In the future "ap:ami" might contain more keys to do more advanced File level actions. Archipelago is being constantly enhanced!
Activity Stream
Archipelago also keeps information about who/how a certain JSON was generated. Depending on how the Ingest/Edit of an ADO happened, this can be automatically generated or added manually (the case for AMI ingests).
The structure is simple and not accumulative because there is also versioning at the ADO (Drupal) level that allows you to look back if needed.
{
"as:generator": {
"type": "Update",
"actor": {
"url": "http:\/\/localhost:8001\/form\/default-descriptive-metadata-ami",
"name": "default_descriptive_metadata_ami",
"type": "Service"
},
"endTime": "2022-03-16T15:51:24-04:00",
"summary": "Generator",
"@context": "https:\/\/www.w3.org\/ns\/activitystreams"
},
}
The "as:generator" Conforms to the Activity Stream Vocabulary Version 2.0 and keeps track of the last Operation executed on an ADO. Edits and Ingests via the Webform Widget will create this automatically using the Canonical URL of the Webform That generated the content and "type" might be either "Update" or "Create". ADOs that were processed via "ap:ami" will have automatically one generated to express the fact that the Original JSON was modified by a Metadata Display Entity. Objects created via AMI and using a Metadata Display Entity can also add via the Twig template syntax the AMI Set ID used to generate the ADO (or Update) allowing the Service URL ("url") to be faceted/searched for (e.g show me all objects ingested via AMI Set with ID 4).
All the other keys, lists, objects. Your Metadata
Anything or everything else (including unknow data, future data, upcoming data) belongs to you. How you name it, how you structure, how it evolves is up to you and the functionality and integration you want. That said, as someone (the writer) that enjoys cooking and had to learn the hardway (experimenting and failing sometmes) the basics before doing proper meals for others to enjoy, we suggest you plan on this before inventing the next Open Schema.
Note: Why the out-of-context Cooking Analogy?
This idea is deeply embedded in our Architecture. We see Metadata as ingredients. Your JSON is your fridge (or pantry or both). Metadata Display Entities, and their Twig Templates, recipes that allow you to pick and choose Ingredients and your Twig coding skills (and filters, functions, loops and conditionals) your basic cooking skills. This analogy has many consequences:
- You can plan upfront and have more ingredients (metadata keys and JSON structures) than what you need/know how to cook, your current Recipes allow. Planning for "your future" needs and skills (and imagination) is a big part of this
- Reading, understanding and testing small changes on the existing recipes will give provide you with future skills and the ability to do similar, incremental better, meals before going for something totally new and complex
- Keeping your Ingredientes RAW and unprocessed is a good idea. You might be tempted to store canned refried beans in the fridge, but that might limit your future options. Maybe try both until you feel more secure, the canned ones AND the dried, single beans too.
- Your use cases might dictate where you start. You cook visually, starting with a very concrete Meal in mind? (means your plan is to make a certain Caserolle - in a less metaphoricall way, a certain well defined output Schema like MODS 3.7). So you need to be sure you have the ingredients that Schema at least requires and know how (or look and copy, MODS is provided already) to process the data. Or you are into a certain type of food? And want to have the most common ingredientes needed around, you might not know how to make all the different dishes but you for sure know Onions (and cutting those) is needed. This are just 2. So many ways of approaching Cooking.
The Open Schema you will get from a Vanilla Archipelago already covers many many uses cases and was developed by a caring team of metadata professionals and practitioners working with Archipelago for a while already. It covers LoD and most Description needs for your Whys, Wheres, When, Who/Whom. Some tips:
- Start by adding new Keys instead of removing existing ones. Existing keys might already be used in your Vanilla Archipelago (in their Processed form) in, e.g the Search API, as Key Name providers (means the target of a JMESPATH query that will be exposed to Drupal as a Field Property), in Views (Filters, Sorting of data). Or in Twig templates (as part of Recipees) that Provide data for Viewers, IIIF V2 and V3, or in your HTML Object Descriptions. Or a Webform configured to Edit/Create new ADOs. All these can be of course modified and adapted, but before spending too much time doing that experiment with adding a new Ingredient and incorporating it to either one of the many Outputs of Archipelago or writing a simple new Recipee that uses it.
- Not all Metadata needs to be used. Want to keep track of your Workflows? Contextual cataloging data? Notes for other metadata professionals in your team? The command line used to capture a WACZ file? You can add that to your JSON. Might all come handy in the future. You don't need to display it at all if you don't want to.
- Experiment with the Existing Webforms and Webform Elements. If you need to allow Metadata that is very unique in structure and values (and validation), try first generating the simplest structure via the shipped Webforms and their elements via the UI. If you feel Webform can not handle then maybe you are structuring it in a too complex way. Test adding and editing. Check the "What if/what ifs". Is your value correctly a string? Would it be better as a boolean or an integer? Think of the "i want many values" v/s this is a single value differences. Because you are in the presence of an OpenSchema you can always change your mind, still better to start on the correct track.
- Give your keys meaningfull names for you/use case/others:
property_1might be hard to document for you. Butoriginal_artifact_in_collectionmight be better (and denotes semantically the value might be a boolean, true of false). Use plural and singular in your naming to denote that something might contain more than one entry. Try to be generic but assertive.mods_modsinfo_namepartis tempting but is already hinting a single original fixed schema. And you might end using the same value (the who) in Dublin Core, IIIF, schema.org, etc outputs. So mybeauthorinstead? This also leads to: sometimes multiple keys are better than many deeply nested ones where understanding. You can keep authors and contributors in separate keys. - Document your keys in the Metadata Display Templates (JSON does not allow comments but also why would you want to document the same in every ADO, would be like writing notes on your Potatoes. The most obvious place to document are your recipees. If adding a new Key add a small note using
{# #}explaining why/what it holds. You can also add Help/Extra info when designing your schema via a the Webform. Each element has extra properties to do so and that way you can also explain others (the ones using the Webform to add/edit) what the purpose of your metadata is. - Use a (or many) local Archipelago Deployment as your experimental Kitchen
Do you have your own Kitchen/cooking tips you want to share? We hope you enjoy the learning process and the many choices Archipelago provides.
Thank you for reading! Please contact us on our Archipelago Commons Google Group with any questions or feedback.
Return to the Archipelago Documentation main page.
Created: November 29, 2022